
As I wrote back then:
I have a couple of concerns. Docs often don’t have enough time TODAY to get through an electronic SOAP note effectively, given workflow constraints. Adding in torrents of “omics” data may be problematic, both in terms of the sheer number of additional potential dx/tx variables to be considered in a short amount of time, and questions of “omics” analytic competency. To that latter point, what will even constitute dx "competency" in the individual patient dx context, given the relative infancy of the research domain? (Not to mention issues of genomic lab QC/QA -- a particular focus that I will have, in light of my 80's lab QC background).
President Obama’s current infatuation with “Precision Medicine” notwithstanding, just dumping bunch of “omics” data into EHRs (insufficiently vetted for accuracy and utility, and inadequately understood by the diagnosing clinician) is likely to set us up for our latest HIT disappointment -- and perhaps injure patients in the process.Relatedly, see my June 29th post "It's not so elementary, Watson." Developments in Health IT. Will IBM's Watson sort through the massive deluge of "omics" data to help significantly to cure cancer?
This stuff has now gotten personal for me. I recently had a genetic test done on a biopsy specimen. Recall from my "Shards" post:
...Without asking me, my urologist sent my biopsy to a company that performs "OncoType dx" genetic assays of biopsies for several cancers, including prostate. He simply wanted to know whether mine was a good candidate for this type of test.The Wiki on the budding "omics" domain:
They just went ahead and ran it, without the urologist's green light order, or my knowledge or consent. I got a call out of the blue one day from a lady wanting to verify my insurance information, and advising me that this test might be "out of your network," leaving me on the hook for some $400, worst case (I subsequently came to learn that it's a ~$4,000 test). I thought it odd, and thought I'd follow up with my doc.
My urologist called me. He was embarrassed and pissed. A young rep from the OncoType dx vendor also called me shortly thereafter. He was in fear of losing his job, having tee'd up the test absent explicit auth.
I've yet to hear anything further. I think they're all just trying to make this one go away. Though, it would not surprise me one whit to see a charge pop up in my BCBS/RI portal one of these days.
The OncoType test result merely served to confirm (expensively -- for someone) what my urologist already suspected. The malignancy aggressiveness in my case is in a sort of "grey zone." The merging composite picture is "don't dally with this."...
Kinds of omics studiesThat's a lot of scientific/technical ground to cover. Will there have be a new medical specialty called "Clinical Geneticology?" Doesn't apparently exist yet.
Genomics
Lipidomics
- Genomics: Study of the genomes of organisms.
- Cognitive genomics examines the changes in cognitive processes associated with genetic profiles.
- Comparative genomics: Study of the relationship of genome structure and function across different biological species or strains.
- Functional genomics: Describes gene and protein functions and interactions (often uses transcriptomics).
- Metagenomics: Study of metagenomes, i.e., genetic material recovered directly from environmental samples.
- Personal genomics: Branch of genomics concerned with the sequencing and analysis of the genome of an individual. Once the genotypes are known, the individual's genotype can be compared with the published literature to determine likelihood of trait expression and disease risk. Helps in Personalized Medicine
- Epigenomics: Study of the complete set of epigenetic modifications on the genetic material of a cell, known as the epigenome. ChIP-Chip and ChIP-Seq technologies used.
Lipidome is the entire complement of cellular lipids, including the modifications made to a particular set of lipids, produced by an organism or system.
Proteomics
- Lipidomics: Large-scale study of pathways and networks of lipids. Mass spectrometry techniques are used.
Proteome is the entire complement of proteins, including the modifications made to a particular set of proteins, produced by an organism or system.
Foodomics
- Proteomics: Large-scale study of proteins, particularly their structures and functions. Mass spectrometry techniques are used.
- Immunoproteomics: study of large sets of proteins (proteomics) involved in the immune response
- Nutriproteomics: Identifying the molecular targets of nutritive and non-nutritive components of the diet. Uses proteomics mass spectrometry data for protein expression studies
- Proteogenomics: An emerging field of biological research at the intersection of proteomics and genomics. Proteomics data used for gene annotations.
- Structural genomics: Study of 3-dimensional structure of every protein encoded by a given genome using a combination of experimental and modeling approaches.
Foodomics was defined in 2009 as "a discipline that studies the Food and Nutrition domains through the application and integration of advanced -omics technologies to improve consumer's well-being, health, and knowledge"
Transcriptomics
Transcriptome is the set of all RNA molecules, including mRNA, rRNA, tRNA, and other non-coding RNA, produced in one or a population of cells.
Metabolism
- Transcriptomics: Study of transcriptomes, their structures and functions.
Nutrition, pharmacology, and toxicology
- Metabolomics: Scientific study of chemical processes involving metabolites. It is a "systematic study of the unique chemical fingerprints that specific cellular processes leave behind", the study of their small-molecule metabolite profiles
- Metabonomics: The quantitative measurement of the dynamic multiparametric metabolic response of living systems to pathophysiological stimuli or genetic modification
Miscellaneous
- Nutritional genomics: A science studying the relationship between human genome, nutrition and health.
- Nutrigenetics studies the effect of genetic variations on the interaction between diet and health with implications to susceptible subgroups
- Nutrigenomics: Study of the effects of foods and food constituents on gene expression. Studies the effect of nutrients on the genome, proteome, and metabolome
- Pharmacogenomics investigates the effect of the sum of variations within the human genome on drugs;
- Pharmacomicrobiomics investigates the effect of variations within the human microbiome on drugs.
- Toxicogenomics: a field of science that deals with the collection, interpretation, and storage of information about gene and protein activity within particular cell or tissue of an organism in response to toxic substances.
- Mitointeractome
- Psychogenomics: Process of applying the powerful tools of genomics and proteomics to achieve a better understanding of the biological substrates of normal behavior and of diseases of the brain that manifest themselves as behavioral abnormalities. Applying psychogenomics to the study of drug addiction, the ultimate goal is to develop more effective treatments for these disorders as well as objective diagnostic tools, preventive measures, and eventually cures.
- Stem cell genomics: Helps in stem cell biology. Aim is to establish stem cells as a leading model system for understanding human biology and disease states and ultimately to accelerate progress toward clinical translation.
- Connectome: The totality of neural connections in the brain.

I guess we'll have to make do for a time with "Genetic Counselors." From the "American Board of Genetic Counseling, Inc." -
How Do I Train To Become a Certified Genetic Counselor?People with these kinds of academic and experiential chops won't be found hanging around the parking lots of Home Depot.
Graduate Requirements
In order to become a Certified Genetic Counselor (CGC©), one must obtain a Master’s degree in Genetic Counseling from an ACGC Accredited Program. Once all requirements have been met, one may apply and sit for the Certification Examination.
At this time, there are no other pathways through which a person can become a Certified Genetic Counselor.
Undergraduate Requirements
Applicants to accredited master degree programs in genetic counseling must have earned a baccalaureate degree from an accredited undergraduate institution prior to applying. Most often individuals that are interested in pursuing a career in genetic counseling are those with a prior interest in or a baccalaureate degree in medical sciences, psychology or healthcare. However, undergraduate degrees in these areas are not required for entrance into an accredited master’s degree program in genetic counseling.
For more information about the genetic counseling profession, visit the National Society of Genetic Counselors at www.nsgc.org.
At least, mercifully, we won't have to worry now about the for-profit diploma mills of Corinthian Colleges et al churning out legions of incompetent and unemployable Omics grads who paid (or borrowed from the feds) tens of thousands of dollars for their worthless AA certs.

Notwithstanding the well-deserved demise of the Corinthian grifters, the new Omics gold rush will surely entice myriad others into the curricular fray.
e.g., none other than the august Stanford (where I was recently 2nd-opinion evaluated for my prostate cancer) is now hawking their online "Stanford Genetics and Genomics Certificate." to wit,

"The Human Genome Project has ushered in a dramatic expansion and acceleration of genetics and genomics research. DNA sequencing technologies promise to advance the field of personalized healthcare, and genome-wide studies have identified numerous genes associated with common diseases and human traits. Commercial applications of genetics research are growing rapidly.Looks interesting. Were I not hemorrhaging cash via my high-deductible BCBS Co-Pays and related OOP this year, I might bite.
The Stanford Genetics and Genomics Certificate program utilizes the expertise of the Stanford faculty along with top industry leaders to teach cutting-edge topics in the field of genetics and genomics. Beginning with the fundamentals of genetics and genomics, participants will build a solid base of knowledge to explore and understand advanced genetics topics of interest.
Who Should Enroll
Earning the Certificate
- Medical sales representatives
- Emerging technology leaders, strategists and venture capitalists who trade within the science-medical space
- R&D managers and new product teams
- Medical practitioners looking to expand their knowledge in the scientific world
- Directors, Managers or Administrators who work in non-scientific roles in scientific environments
Participants have the flexibility of taking individual courses within the program or earning the Stanford Genetics and Genomics Certificate by completing 2 core courses and 4 elective courses. Courses may be taken at your own pace online. We strongly recommend that participants complete Fundamentals of Genetics: The Genetics You Need to Know (XGEN101) and Genomics and the Other Omics: The Comprehensive Essentials (XGEN102).
Each course consists of online lecture videos, self-paced exercises, and a final exam. Lecture videos are presented in short segments for easier viewing and frequent self-reflection.
Prerequisites
Tuition
- 5 years of work experience, preferably in science or tech related fields
- Bachelor’s degree or equivalent
- High school level knowledge of biology and chemistry
- An investigative and scientific spirit
$695 per Required CourseTime to Complete Certificate
$495 per Elective Course
$75 one-time document fee
Courses are self-paced. Each course is available for 90 days after date of enrollment.
But, when I look at their coursework, all of it -- focused on the basic and applied science -- assumes that genetic lab assays are reliable -- accurate and precise (they're not the same thing). Coming from a forensic lab background, I don't share such sanguinity. Last time I checked there were no federal QA standards regulating commercial genetic testing. That does not portend well. Do a Google search on "genetic testing quality assurance." You find dated stuff like this above the fold. First, from a CLIA slide deck.

That's pretty sad.
Then, a 16 year old PubMed cite referencing JAMA:
JAMA. 1999 Mar 3;281(9):835-40.Doesn't exactly give me Warm Fuzzies. I'll have to keep digging.
Quality assurance in molecular genetic testing laboratories.
McGovern MM1, Benach MO, Wallenstein S, Desnick RJ, Keenlyside R.
Abstract
CONTEXT:
Specific regulation of laboratories performing molecular genetic tests may be needed to ensure standards and quality assurance (QA) and safeguard patient rights to informed consent and confidentiality. However, comprehensive analysis of current practices of such laboratories, important for assessing the need for regulation and its impact on access to testing, has not been conducted.
OBJECTIVE:
To collect and analyze data regarding availability of clinical molecular genetic testing, including personnel standards and laboratory practices.
DESIGN:
A mail survey in June 1997 of molecular genetic testing laboratory directors and assignment of a QA score based on responses to genetic testing process items.
SETTING:
Hospital-based, independent, and research-based molecular genetic testing laboratories in the United States.
PARTICIPANTS:
Directors of molecular genetic testing laboratories (n = 245; response rate, 74.9%).
MAIN OUTCOME MEASURE:
Laboratory process QA score, using the American College of Medical Genetics Laboratory Practice Committee standards.
RESULTS:
The 245 responding laboratories reported availability of testing for 94 disorders. Personnel qualifications varied, although all directors had doctoral degrees. The mean QAscore was 90% (range, 44%-100%) with 36 laboratories (15%) scoring lower than 70%. Higher scores were associated with test menu size of more than 4 tests (P = .01), performance of more than 30 analyses annually (P = .01), director having a PhD vs MD degree (P = .002), director board certification (P = .03), independent (P <.001) and hospital (P = .01) laboratories vs research laboratory, participation in proficiency testing (P<.001), and Clinical Laboratory Improvement Amendment certification (P = .006). Seventy percent of laboratories provided access to genetic counseling, 69% had a confidentiality policy, and 45% required informed consent prior to testing.
CONCLUSION:
The finding that a number of laboratories had QA scores that may reflect suboptimal laboratory practices suggests that both personnel qualification and laboratory practice standards are most in need of improvement to ensure quality in clinical molecular genetic testing laboratories.
For one thing, I turn to what looks to be a timely (2015 release) and otherwise authoritative resource (expensive too, $142 in hardcover, $77 Kindle).

Laboratory process, data generation, and quality control
Preanalytical and quality laboratory processes
The critical difference distinguishing a clinical genomic sequencing service from sequencing performed in a research setting is the establishment, implementation, and documentation of Standard Operation Procedures (SOPs) that ensure integrity and quality of samples, data, patient privacy, interpretation, and final reports returned to the physician. It is also essential to have an available staff consisting of licensed and trained professionals, including genetic counselors, clinical genetic molecular biologists, medical geneticists, and bioinformaticians; in addition to working with each other, many members of this team will need to be able to work directly with ordering physicians and to produce a final report that positions can use to make patient healthcare decisions. The application of genomic sequencing services to the medical field requires physicians and patients to be adequately informed and trained to handle the information presented in the final report, while also limiting the data that may not be useful or is distracting from the patient’s healthcare decisions.
While a major focal point of running a clinical genomic sequencing facility centers upon ensuring the accuracy of data and report generation, the majority of errors in a clinical laboratory are made during the preanalytical phase of performing clinical tests. The bulk of laboratory errors occur in the pre-analytical phase (~60%), with the post-analytical phase being the second most problematic (~25%). The majority of pre-analytical errors can be attributed to sample handling and patient identification. Many of these errors can be avoided by developing a chain of custody program that is scalable for the number of samples entering the lab. Examples include sample collection kits that include matched, barcoded sets of tubes, forms, and instructions for proper patient handling, the implementation of a laboratory information management system, and regular, ongoing training and assessment of staff performance. Many other suggestions exist for how to develop high quality processing and procedures that minimize the probability of such errors.
Given the complexity and personalized nature of each genomic sequencing tests, appropriate tools should be developed to optimize communication between clinical genomics laboratory personnel, and the physician to ensure the test is being appropriately ordered and analyzed for the patient. Ideally, genetic counselors should be available to communicate with ordering physicians regarding why the test is being ordered, what the deliverable will be, and how the results can be used appropriately. It is also appropriate to offer training and support tools (for example, podcasts/downloadable instructions) to the ordering physician in order to prepare them for navigating through multiple steps of this process. While onerous for both the laboratory and physician, such steps taken ahead of test ordering are likely to optimize the results and significantly reduce probability of error, confusion, and misunderstanding.
Test results from genomic sequencing can offer much more data than the position requires for patient diagnosis, which can be distracting and potentially stressful to the patient. In order to circumvent issues with excess data, the clinical genomic sequencing laboratory should be forthright in verifying the types of information the patient/physician would prefer to receive or not to receive. The physician or genetic counselor should consider the specific situation of the patient when assessing the appropriateness of potentially delivering sensitive incidental findings, such as susceptibility to late onset conditions, cancer, or concerns about non-paternity. The American College of Medical Genetics and Genomics (ACMG) Working Group on incidental findings in clinical Exome and GS recently released a list of genes and categories of variance that should be conveyed in a clinical genomics report, even if found as secondary or incidental results. The ACMG Working Group feels that although these variants may not be immediately necessary for the patient diagnosis decision, they could be critical for the patient’s well-being and should not be withheld. Position training should therefore include how to assist the patient in making decisions and what should be reported, and how to subsequently complete a required informed consent signed by the patient which outlines the terms of the genomic test request. Since patient genomic sequencing results in a very complex data set with a plethora of information, tools should be developed to enable easy navigation of results as questions arise, and support should be offered to the position before the test results are delivered in order to both maximize value for the patient and minimize the time and effort set forth by the physician.
Patient sample tracking can be one of the most difficult components of clinical genomic sequencing because the process requires many steps that occur over a period of several days, among several people, and the process must protect the patient’s privacy in accordance with the Health Insurance Portability and Accountability Act (HIPAA) regulations. However, this challenge is not specific to GS, and has been recognized as an ongoing challenge for all clinical laboratories.
Analytical
The processing of one genome can be divided up into three categories: wet lab processing, bioinformatics analysis, and interpretation and report generation. As the authors of this chapter use an Illumina platform, the details describe below are consistent with that platform; though other platforms vary in specifics of certain steps, the general principles nonetheless remain the same. These principles include DNA extraction, DNA shearing and size selection, ligation of oligonucleotide adapters to create a size selected library, and physical isolation of the library fragments during amplification and sequencing.
As discussed more fully in Chapter 1, for library preparation, intact gDNA is first sheered randomly. Prior to adapter labeling this year gDNA is blunt ended and and an adenosine overhang is created through a “dATP” tailing reaction. The adapters are comprised of the sequencing primer and an additional oligonucleotide that will hybridize to the flow cell. After adapter ligation the samples is size selected by gel electrophoresis, gel extracted, and purified.
After the library has been constructed, it is denatured and loaded onto a glass flow cell where it hybridizes to a lawn of oligonucleotides that are complementary to the adapters on an automated liquid handling instrument that adds appropriate reagents at appropriate times and temperatures. The single-stranded, bound the library fragments are then extended and the free and cyber dies to the neighboring lawn of complementary oligonucleotides. This “bridge” is then grown into a cluster through a series of PCR amplification’s. In this way, a cluster of approximately 2000 clonally amplified molecules is formed; across a single lane of a flow cell, there can be over a 37 million individual amplified clusters. The flow cell is then transferred to the sequencing instrument. Depending on the target of the sequencing assay, it is also possible to perform a paired-end read, where the opposite end of the fragment is also sequenced.
As was mentioned previously, NGS works by individually sequencing fragmented molecules. Each of these molecules represents a haploid segment of DNA. In order to ensure that both chromosomes of a diploid region of DNA are represented, it is therefore necessary to have independent sampling events. This is a classic statistical problem, in which the number of independent sampling events required to have a given probability of detecting both chromosomes can be represented by the formula:
In this case, the number of independent sampling events needed to detect a variant is dependent on the number of total sampling events and the number of times each allele is detected, where N is the number of sampling events, X is the number of alternative observations, and P equals allele 1 and Q equals allele 2, each of which should (in constitutional testing) be present in equal proportions. Using this principle, it is possible to estimate the minimum number of sampling events required to have confidence that the call represents both chromosomes, and therefore if a variant were present, it would be detected. However, this formula represents the ideal, in which all calls are perfect; in reality calls are not always perfect, so additional quality monitoring of the call, and how well the call is mapped to a position in the genome, must also be considered. During assay validation, the number of independent sampling events, typically referred to as the depth of coverage, should be measured on known samples to understand what thresholds of depth result in what confidence of detection. In the Illumina Clinical Services Laboratory (ICSL), evaluation of multiple known samples run at various steps and a subsample of bootstrapping analysis showed that the results generally track well with the hypothetical expectations. Based on these results, the average coverage of a call at 30-fold depth results in greater than 99.9% sensitivity and greater than 99.99% specificity of variant detection however, when the average call is made at 30-fold depth, something less than half of the total calls are made at less than 30-fold depth, and thus have a lower sensitivity and specificity for variant detection. Using a minimal depth of coverage at any position to make a call, specifically tenfold depths, yields a 97% sensitivity and 99.9% specificity. Mapping the distribution of calls for every call made makes it possible to evaluate the corresponding confidence for any given individual call, and essentially back-calculate the required average depth of coverage required to meet specific sensitivity and specificity test metrics. The same approach can be applied to the formula for non-diploid situations, for example, for detection of header applies me a somatic variant, or sequence variants in different stranger of microbes…
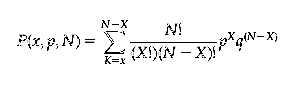

Figure 2.1 [click image to enlarge] For any given average depth of coverage for the genome, the coverage at individual loci will be distributed around that average. This graph display the distribution of coverage when the average depth of coverage for the genome is about 40-fold. Since most bioinformatics pipelines cannot reliably detect variants at positions with fewer than 10 independent sampling events (less than the 10-fold depth of coverage), the graph does not include that region of the distribution.I like that they take a broad view of "quality," one going beyond the tech details of assay accuracy and precision. They make a distinction between "research" analytics and "commercial," but there' no mention of a "forensic" level of reliability (but, maybe it's addressed further down in the book).
The genomic sequencing process must be tightly monitored with quality assessments at each step to ensure that the sample is progressing with the highest possible quality. The steps of the sequencing process that for which monitoring is useful include DNA extraction, library preparation, cluster generation, and the sequencing run. Each one of these steps must be assayed for quality. In each case, the quality thresholds established during validation, and the average performance metrics of other samples should be compared to the sample being processed; if a sample is showing metrics outside of the normal range, the sample should be investigated.
Robotics and automation are valuable additions that can be made to protocol to minimize the possibility of human error. DNA extraction, library preparation, and cluster generation can be performed with a robot. New or generation sequencing machines combine these steps by performing both the cluster generation and sequencing processes, further limiting the possibility of human error in the transfer of the flow cell between steps. Future advances to further combine the sequencing laboratory steps with automation will increasingly assure a reduction in potential errors. In fact, it is easy to imagine that, in the very near future, sequencing will be form performed with full automation that does not require human touch after the first sample loading.
Quality control of clinical genomic sequencing services is an ongoing responsibility that should be continually evolving based on monitoring and evaluation, as well as externally monitored via proficiency testing, in which laboratories using similar or or follow gust techniques compare their results. The use of appropriate metrics and controls for each step of the process will ensure robust sequencing runs and the ability to identify where and how errors may have arisen. External controls, such as lambda DNA fragments, can be spiked into samples and follow the process additionally, controls internal to a sample can also be used effectively. In addition to controls, specific run and performance metrics should be established during the validation phase that can be used to monitor individual run performance and ensure that the equipment and chemistries are performing as expected; and or followed us assay such as micro-array analysis is one such approach, but other possibilities exist by comparing the con cordons of calls from a genomic level micro-array, not only can a measure of quality of the sequence be obtained, but also sample swabs or contaminations can be detected…
Tightwad here didn't buy this book (yet). I read this excerpt in via Dragon from the extensive Amazon "Look Inside" sample. My lab QC chops may be a bit dated, but, not all that much, it would seem after reading this. Instrumentation and assay targets may have indeed advanced materially, but the fundamental concepts of lab QC/QA remain as they have been for decades. Reference stds (internal and external), matrix and DI spikes, dupes, blanks, etc.
This was interesting:
"Robotics and automation are valuable additions that can be made to protocol to minimize the possibility of human error. DNA extraction, library preparation, and cluster generation can be performed with a robot."See my post "The Robot will see you now -- assuming you can pay."
On the "Sensitivity" and "Specificity" stuff: I've written about that elsewhere in a different context (scroll down).
More broadly, there's a ton to watch (and question) with respect to the burgeoning field of Omics entrepreneurs. "Omicology.com?" Someone has squatted it.

Googling "Geneticology" turns up this website.

Pretty much consumer-facing information. Nothing on the organization behind it.
Stay tuned.
___
More to come...
No comments:
Post a Comment